第6章 Spark 内核调度
DAG
有向无环图(Directed Acyclic Graph)
Spark 的核心是根据 RDD 来实现的,Spark Scheduler 则为 Spark 核心实现的重要一环,其作用就是任务调度。Spark 的任务调度就是如何组织任务去处理 RDD 中每个分区的数据,根据 RDD 的依赖关系构建 DAG,基于 DAG 划分 Stage, 将每个 Stage 中的任务发到指定节点运行。基于 Spark 的任务调度原理,可以合理规划资源利用,做到尽可能用最少的资源高效地完成任务计算。
[[2021-12-15-SparkCore#RDD 的缓存|RDD 的缓存]] 对应的 DAG:
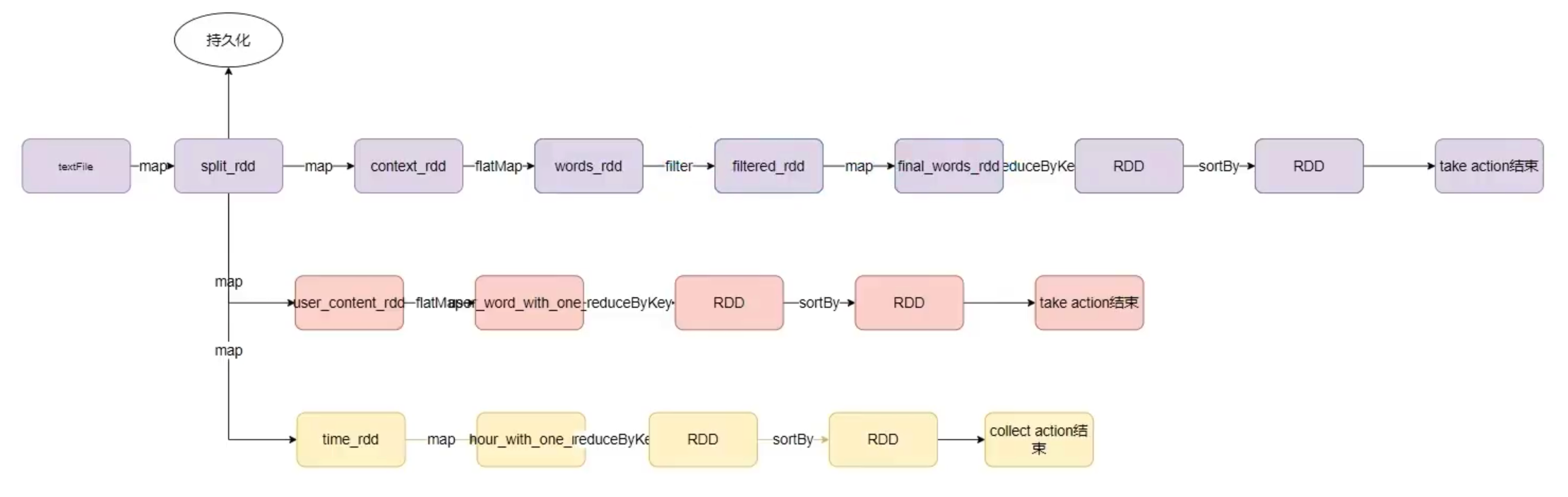
结论:1个Action = 1个DAG = 1个Job
宽窄依赖和阶段划分
- 窄依赖:父 RDD 的一个分区,将数据全部发给子 RDD 的一个分区(一对一、多对一)
- 宽依赖:父 RDD 的一个分区,将数据发给子 RDD 的多个分区(一对多),又称
shuffle
对于 Spark 来说,会根据 DAG,按照宽依赖划分不同的阶段
划分依据:从后向前,遇到宽依赖,就划分出一个阶段,称之为 stage
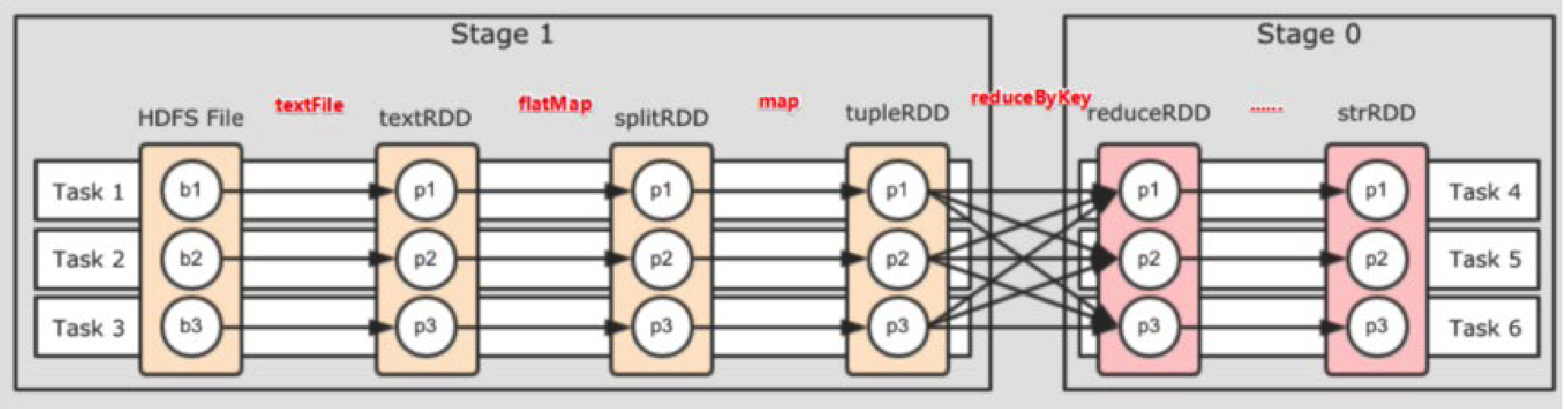
内存迭代计算
Spark 默认受到全局并行度的限制,除了个别算子有特殊分区情况,大部分的算子,都会遵循全局并行度的要求,来规划自己的分区数。
Spark 为什么比 MapReduce 快
- 编程模型上 Spark 算子丰富
- 算子交互上和计算上可以尽可能多的内存计算而非磁盘迭代。
Spark 并行度
并行度:在同一时间内,有多少个 task 在同时运行
全局并行度-推荐
配置文件中:
# conf/spark-defaults.conf
spark.default.parallelism 100
在客户端提交参数中:
spark-submit --conf "spark.default.parallelism=100"
在代码中设置:
conf = SparkConf()
conf.set("spark.default.parallelism", "100")
针对 RDD 的并行度设置-不推荐
只能在代码中,算子:
- repartition
- coalesce
- partitionBy
并行度规划建议
结论:设置为 CPU 总核心数的2~10倍
Spark 的任务调度
Spark 程序的调度流程如下:
- Driver 被构建出来
- 构建 SparkContext(执行环境入口对象)
- 基于 DAG Scheduler(DAG 调度器)构建逻辑 Task 分配
- 基于 TaskScheduler(Task 调度器)将逻辑 Task 分配到各个 Executor 上,并监控它们
- Executor 被 TaskScheduler 管理监控,听从它们的指令干活,并定期汇报进度
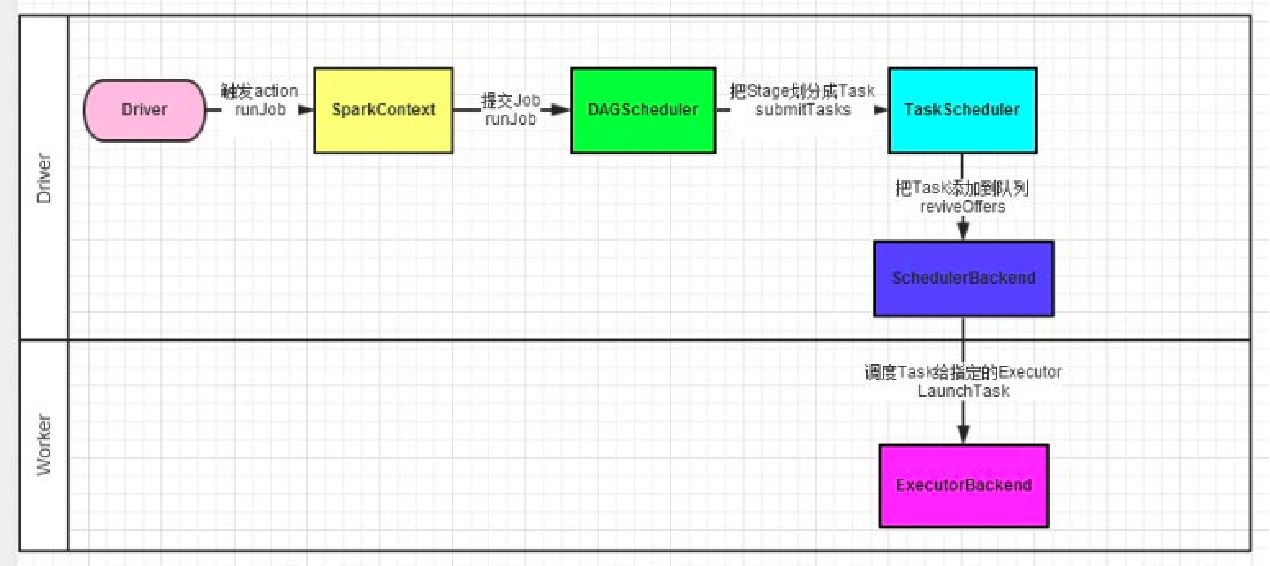
DAG 调度器
工作内容:将逻辑的 DAG 图进行处理,最终得到逻辑上的Task划分.
Task 调度器
工作内容:基于 DAG 调度器的产出,来规划逻辑的 task,应该在哪些物理的 executor 上运行,以及监控管理它们的运行。
拓展
spark官方概念名词大全

层级关系疏离
- 一个 Spark 环境可以运行多个 Application
- 一个用户程序运行起来,会成为一个 Application
- Application 内部可以有多个 Job
- 每个 Job 由一个 Action 产生,并且每个 Job 有自己的 DAG 执行图
- 一个 Job 的 DAG 图会给予宽窄依赖划分成不同的 Stage
- 不同 Stage 内基于分区数量,形成多个并行的内存迭代管道
- 每一个内存迭代管道形成一个 Task
Spark Shuffle
Spark 在 DAG 调度阶段会将一个 Job 划分为多个 Stage,上游 Stage 做 map 工作,下游 Stage 做 reduce 工作,其本质上还是 MapReduce 计算框架。
Shuffle 是连接 map 和 reduce 之间的桥梁,它将 map 的输出对应到 reduce 输入中,涉及到序列化反序列化、跨节电网络 IO 以及磁盘读写 IO 等。
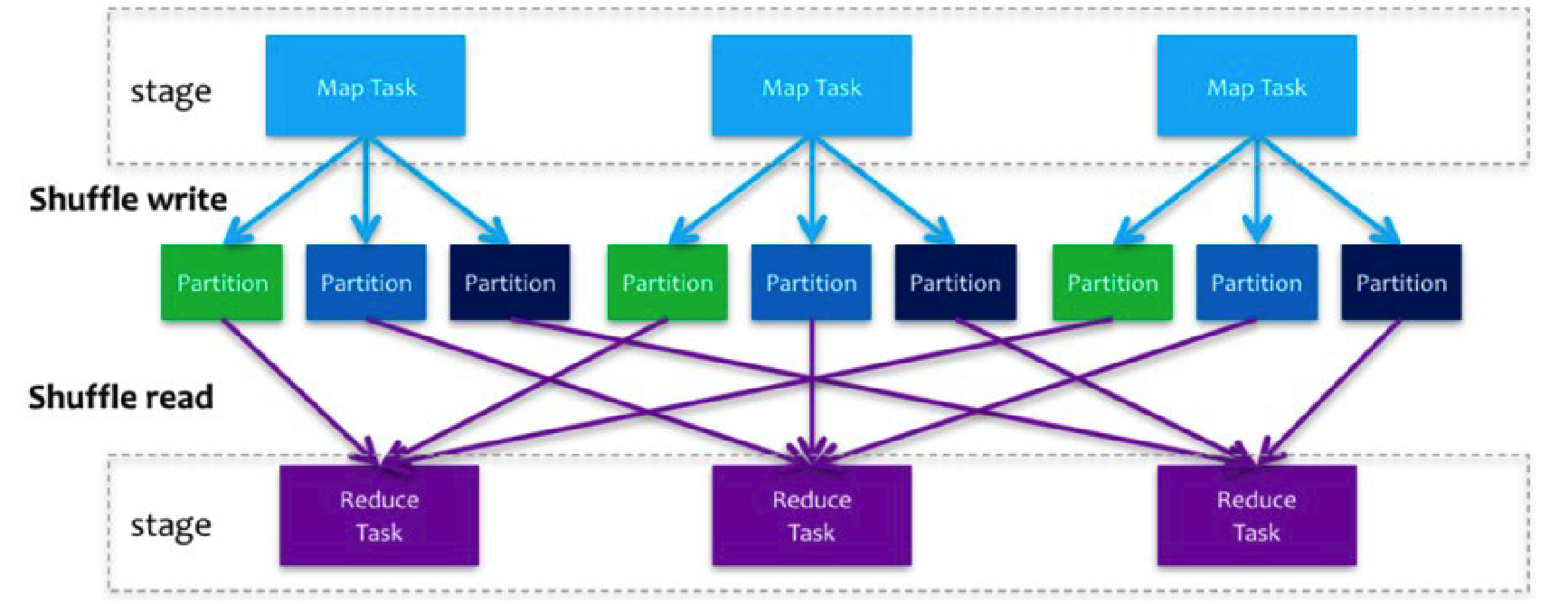
在 Shuffle 过程中,提供数据的称之为 Map 端(Shuffle Write);接受数据的称之为 Reduce 端(Shuffle Read)
Hash Shuffle
| 未经优化的HashShuffleManager | 优化后的HashShuffleManager | |
|---|---|---|
| 示例 | 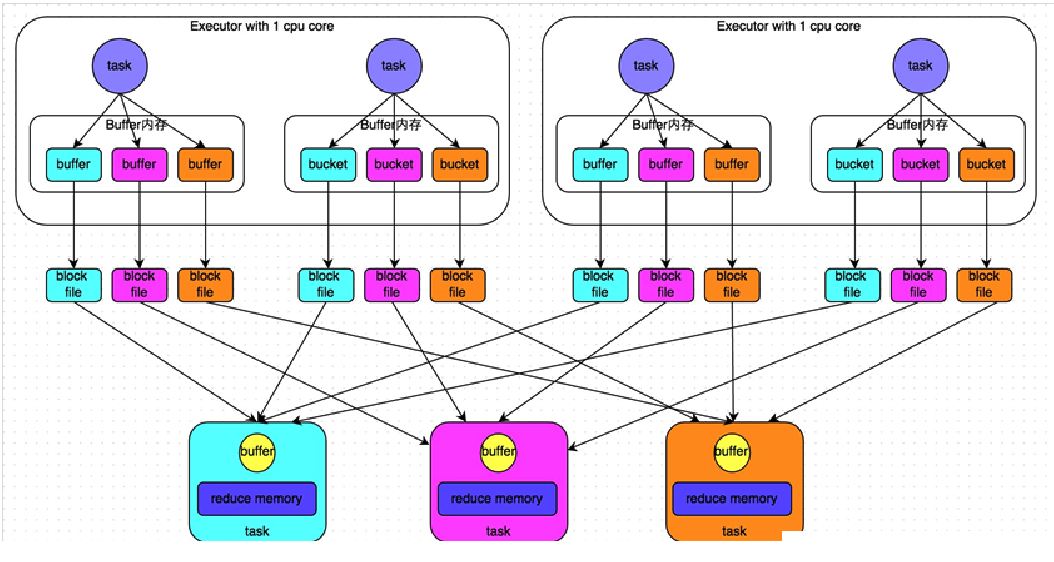 |
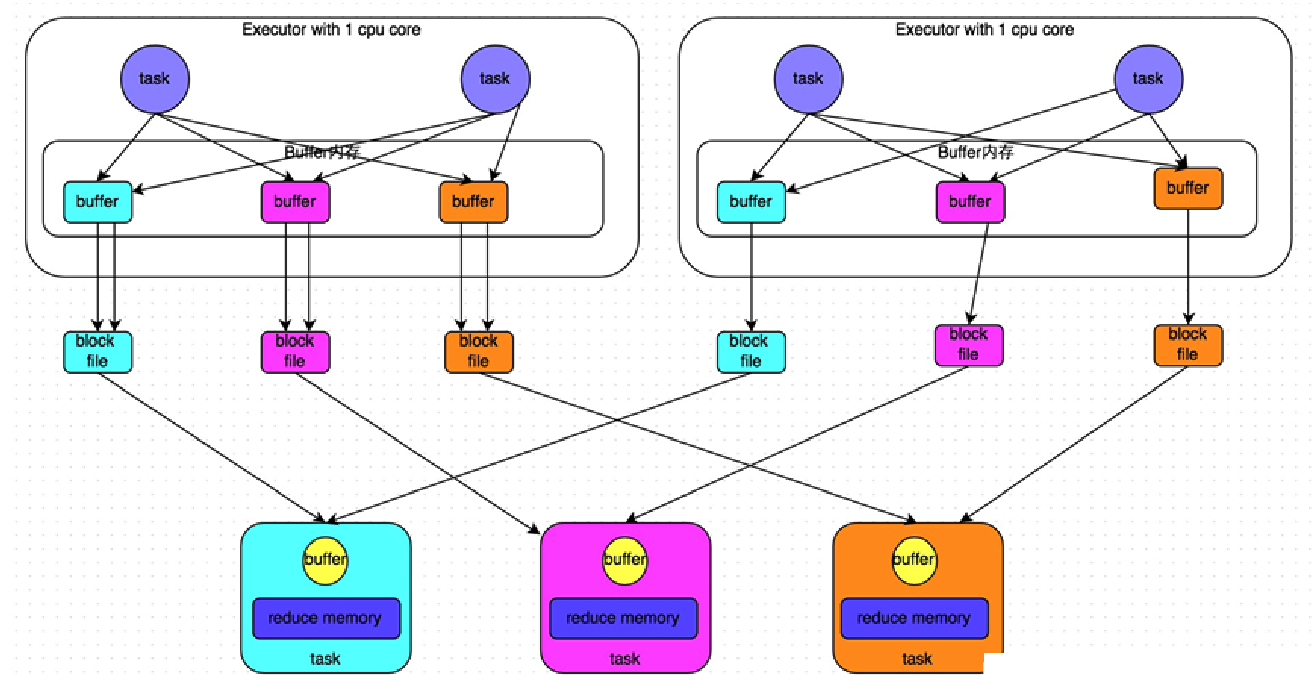 |
| 磁盘文件数量1 | m*n | k*n |
优化在于:
- 在一个 Executor 内,不同 Task 共享 buffer 缓冲区
- 减少了缓冲区和磁盘文件的数量,提高性能
Sort Shuffle
| 普通机制的SortShuffleManager | ByPass机制的SortShuffleManager | |
|---|---|---|
| 示例 | 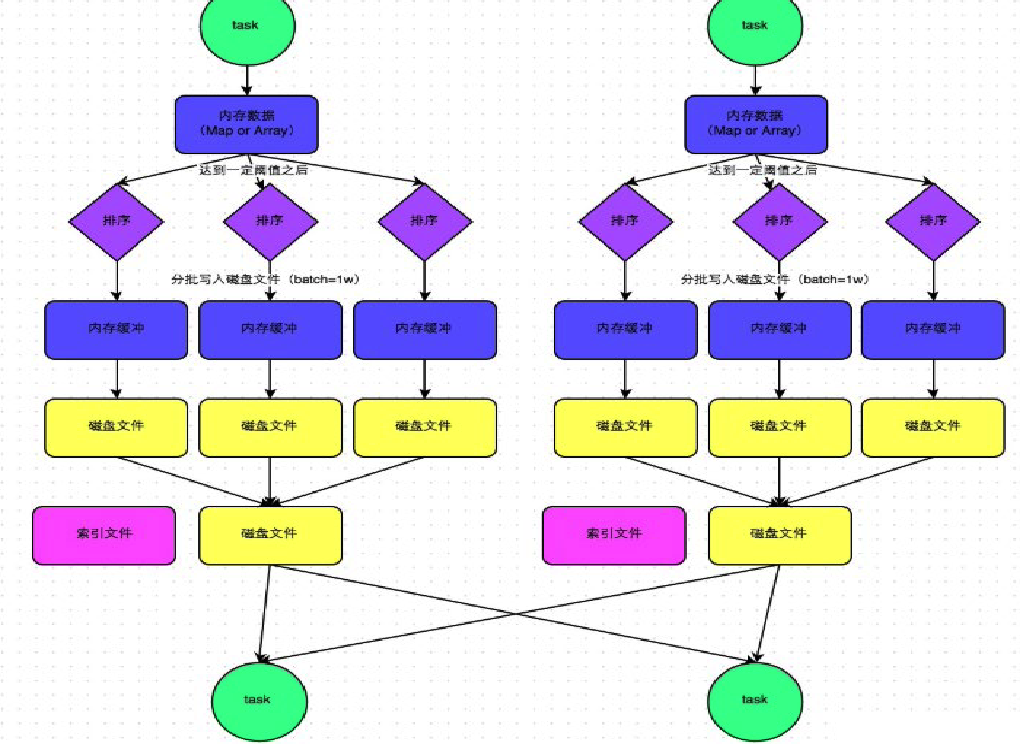 |
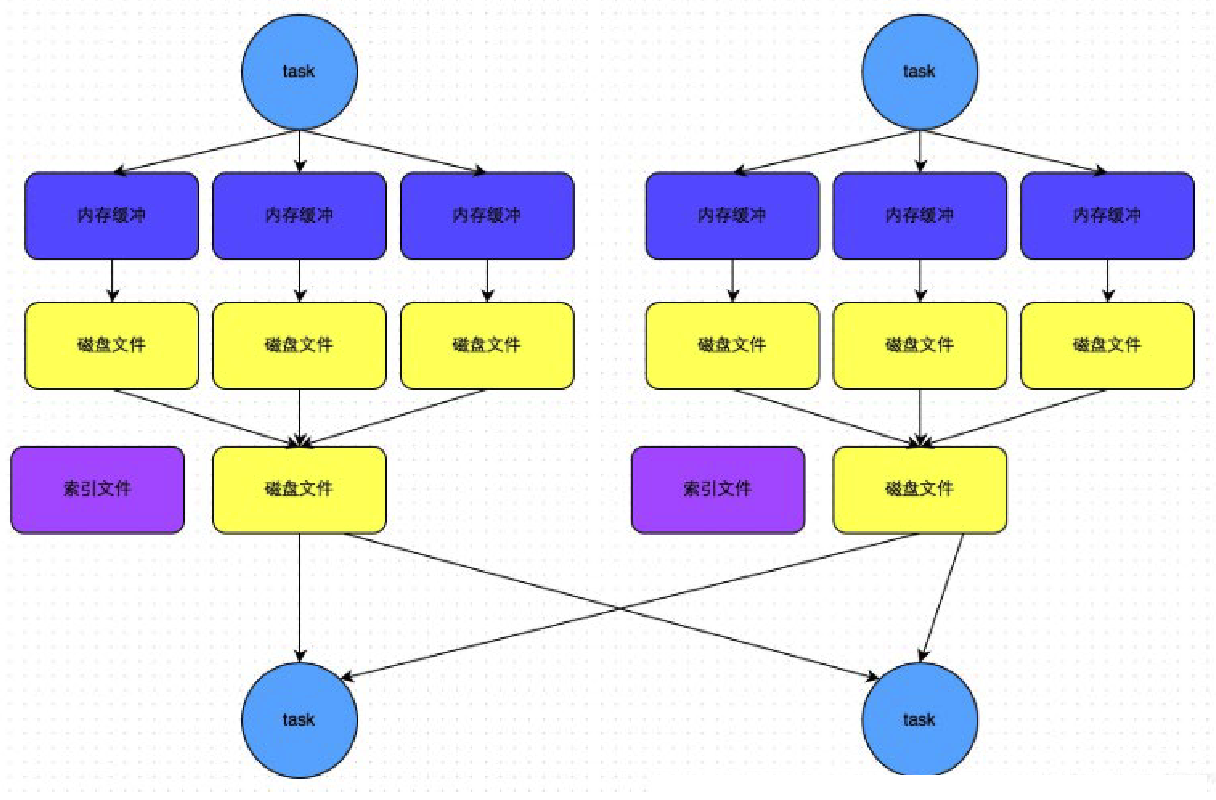 |
- SortShuffleManager 进一步减少了磁盘文件数量,以节省网络 IO 的开销。
- SortShuffleManager 分为普通机制和 bypass 机制。
- 普通机制在内存数据结构(默认为5M)完成排序,会产生2M个磁盘小文件。
- 而当 shuffle map task 数量小于
spark.shuffle.sort.bypassMergeThreshold参数的值,或者算子不是聚合类的 shuffle 算子(比如 reduceByKey)的时候会触发 SortShuffle 的 bypass 机制,SortShuffle 的 bypass 机制不会进行排序,极大地提高了性能。
Shuffle 的配置选项
spark shuffle 调优:主要是调整缓冲的大小,拉取次数重试重试次数与等待时间,内存比例分配,是否进行排序操作等等
spark.shuffle.file.buffer:
参数说明:该参数用于设置 shuffle write task 的 BufferedOutputStream 的 buffer 缓冲大小(默认是32K)。将数据写到磁盘文件之前,会先写入buffer缓冲中,待缓冲写满之后,才会溢写 到磁盘。
调优建议:如果作业可用的内存资源较为充足的话,可以适当增加这个参数的大小(比如64k),从而减少shuffle write过程中溢写磁盘文件的次数,也就可以减少磁盘 IO 次数,进而提升性 能。在实践中发现,合理调节该参数,性能会有1%~5%的提升。
spark.reducer.maxSizeInFlight:
参数说明:该参数用于设置 shuffle read task 的 buffer 缓冲大小,而这个 buffer 缓冲决定了每次能够拉取多少数据。(默认48M)
调优建议:如果作业可用的内存资源较为充足的话,可以适当增加这个参数的大小(比如96M),从而减少拉取数据的次数,也就可以减少网络传输的次数,进而提升性能。在实践中发现 ,合理调节该参数,性能会有1%~5%的提升。
spark.shuffle.io.maxRetries 和 spark.shuffle.io.retryWait:
spark.shuffle.io.maxRetries:shuffle read task 从 shuffle write task 所在节点拉取属于自己的数据时,如果因为网络异常导致拉取失败,是会自动进行重试的。该参数就代表了可以重试的最大次数。(默认是3次)
spark.shuffle.io.retryWait:该参数代表了每次重试拉取数据的等待间隔。(默认为5s)
调优建议:一般的调优都是将重试次数调高,不调整时间间隔。
spark.shuffle.memoryFraction:
参数说明:该参数代表了 Executor 内存中,分配给 shuffle read task 进行聚合操作内存比例。
spark.shuffle.manager:
参数说明:该参数用于设置 shufflemanager 的类型(默认为sort)。
Spark1.5x以后有三个可选项:
- Hash:spark1.x 版本的默认值,HashShuffleManager
- Sort:spark2.x版本的默认值,普通机制,当shuffle read task 的数量小于等于 spark.shuffle.sort.bypassMergeThreshold 参数,自动开启 bypass 机制
spark.shuffle.sort.bypassMergeThreshold:
参数说明:当 ShuffleManager 为 SortShuffleManager 时,如果 shuffle read task 的数量小于这个阈值(默认是200),则 shuffle write 过程中不会进行排序操作。
调优建议:当你使用 SortShuffleManager 时,如果的确不需要排序操作,那么建议将这个参数调大一些。
总结
- SortShuffle 对比 HashShuffle 可以减少很多的磁盘文件,以节省网络 IO 的开销
- SortShuffle 主要是对磁盘文件进行合并来进行文件数量的减少,同时两类 Shuffle 都需要经过内存缓冲区溢写磁盘的场景,所以可以得知,尽管 Spark 是内存迭代计算框架,但是内存迭代主要在窄依赖中。在宽依赖(Shuffle)中磁盘交互还是一个无可避免的情况。所以,我们要尽量减少 Shuffle 的出现,不要进行无意义的 Shuffle 计算。
-
上游 task 数量:m;下游 task 数量:n;上游 executor 数量:k(m>=k) ↩