SparkSQL 的运行流程
SparkRDD 的执行流程回顾
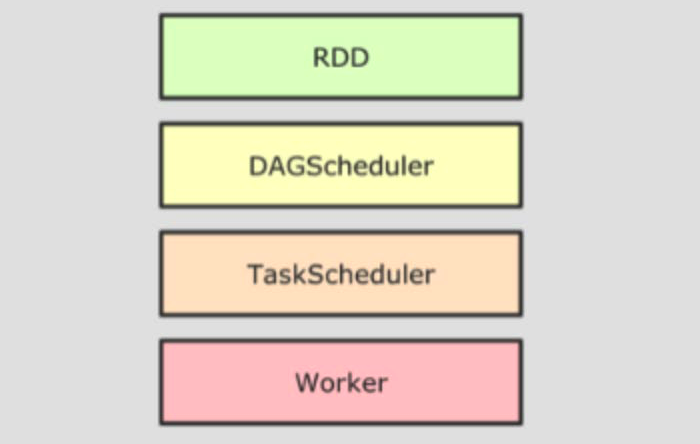
- driver 提交任务
- DAG 调度器逻辑任务
- Task 调度器任务分配和管理监控
- Worker 干活
SparkSQL 的自动优化
RDD 的运行会完全按照开发者的代码运行,如果开发者水平有限,RDD 的执行效率也会受到影响。
而 SparkSQL 会对代码执行“自动优化”,以提高代码运行效率。
DataFrame 可以被优化,是因为它固定是二维表结构,而 RDD 内的数据类型是不固定的。
SparkSQL 的自动优化依赖于 Catalysty优化器
Catalyst 优化器

- 解析 SQL,并且生成 AST(抽象语法树)
- 在 AST 中加入元数据信息,为优化做准备
- 对已经加入元数据的 AST,输入优化器,进行优化。
- 谓词下推(Predicate Pushdown):将过滤表达式尽可能移动至靠近数据源的位置,以使真正执行时能直接跳过无关的数据。
- 列裁剪(Column Pruning):尝试从逻辑计划中去掉不需要的列,从而减少读取数据的量。
- 更多优化:
org.apache.spark.sql.catalyst.optimizer.Optimizer
- 优化后的逻辑计划,还不能直接运行,需要生成物理计划,从而生成 RDD 来运行。
- 在生成物理计划的时候,会经过“成本模型”再次执行优化。
- 可以使用
queryExecution方法查看逻辑计划,使用explain方法查看物理计划
SparkSQL 的执行流程
- 提交 SparkSQL 代码
- Catalyst 优化
- 生成原始 AST 语法树
- 标记 AST 元数据
- 进行谓词下推和列值裁剪以及其它方面的优化作用在 AST 上
- 将最终 AST 的到,生成执行计划
- 将执行计划翻译为 RDD 代码
- Driver 执行环境入口构建(SparkSession)
- DAG 调度器规划逻辑任务
- Task 调度分配逻辑任务到具体 Executor 上工作并监控管理任务
- Worker 干活
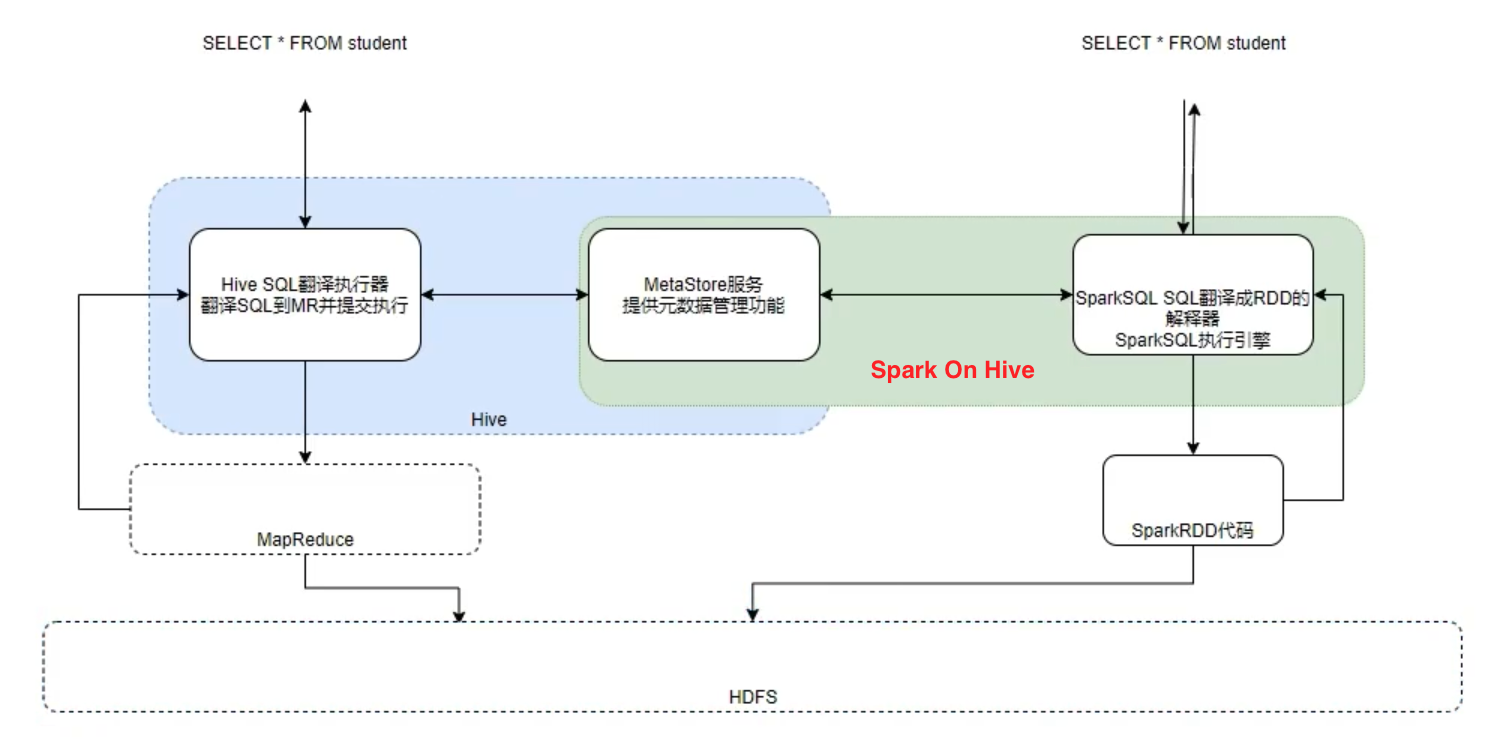
SparkSQL 整合 Hive
原理
对于 Hive,就两件东西:
- SQL 优化翻译器(执行引擎),翻译 SQL 到 MapReduce 并提交到 YARN 执行
- MetaStore 元数据管理中心
对于 Spark on Hive:
- Spark 提供执行引擎能力
- Hive 的 MetaStore 提供元数据管理功能
配置
在 spark 的 conf/hive-site.xml 中修改以下配置:
- hive.metastore.warehouse.dir
- hive.metastore.uris
在代码中集成
spark = SparkSession.builder.\
appName("myApp").\
master("local").\
config("spark.sql.shuffle.partitions", "4").\
config("spark.sql.warehouse.dir", "...").\
config("hive.metastore.uris", "...").\
enableHiveSupport().\ # 启动Hive支持
getOrCreate()
分布式 SQL 引擎配置
概念
Spark 中有一个服务叫做:ThirftServer,可以启动并监听 10000 端口
这个服务队外提供功能,我们可以用数据库工具或者代码连接上来,直接写 SQL 即可操作 Spark。
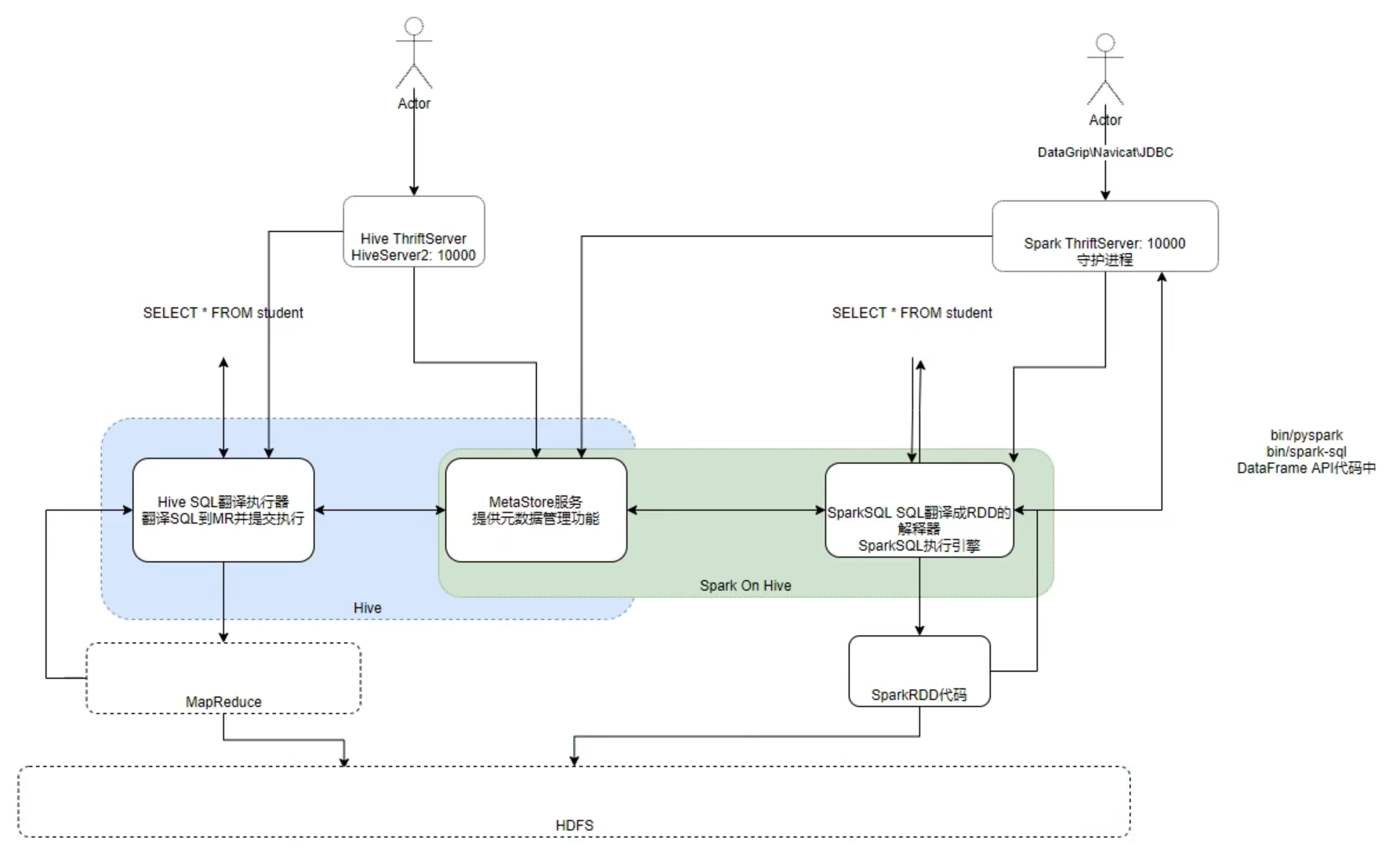
客户端工具连接
启动 ThirftServer
export HIVE_SERVER2_THRIFT_PORT=<listening-port>
export HIVE_SERVER2_THRIFT_BIND_HOST=<listening-host>
./sbin/start-thriftserver.sh \
--master <master-uri> \
...
或者
./sbin/start-thriftserver.sh \
--hiveconf hive.server2.thrift.port=<listening-port> \
--hiveconf hive.server2.thrift.bind.host=<listening-host> \
--master <master-uri>
...
客户端工具连接
〈略〉
代码 JDBC 连接
# coding:utf8
# 以JDBC模式 连授分布式Spark引擎
# 这个包是用来 以python代码 连接hive使用
from pyhive import hive
if __name__ = '__main__':
# 获取到 Hive(Spark Thriftserver) 的连接
conn = hive.Connection(host="node1", port=10000, username='hadoop')
# 获取一个游标对象,用来执行sql
cursor = conn.cursor()
# 执行sql 使用executor API
cursor.execute("SELECT * FROM test")
# 执行后,使用fetchall API 获取全郎的返回值,返回值是一个List对象
result = cursor.fetchall()
# 打印输出
print(result)