掌握 Spark3.0 新特性
Adaptive Query Execution 自适应查询(SparkSQL)
通过在“运行时”对查询执行计划进行优化,允许 Planner 在运行时执行可选计划,这些可选计划将会基于运行时数据统计进行动态优化,从而提高性能。
set spark.sql.adaptive.enabled = true;
AQE 主要提供了三个自适应优化:
- 动态合并 Shuffle Partitions
- 动态调整 Join 策略
- 动态优化倾斜 Join(Skew Joins)
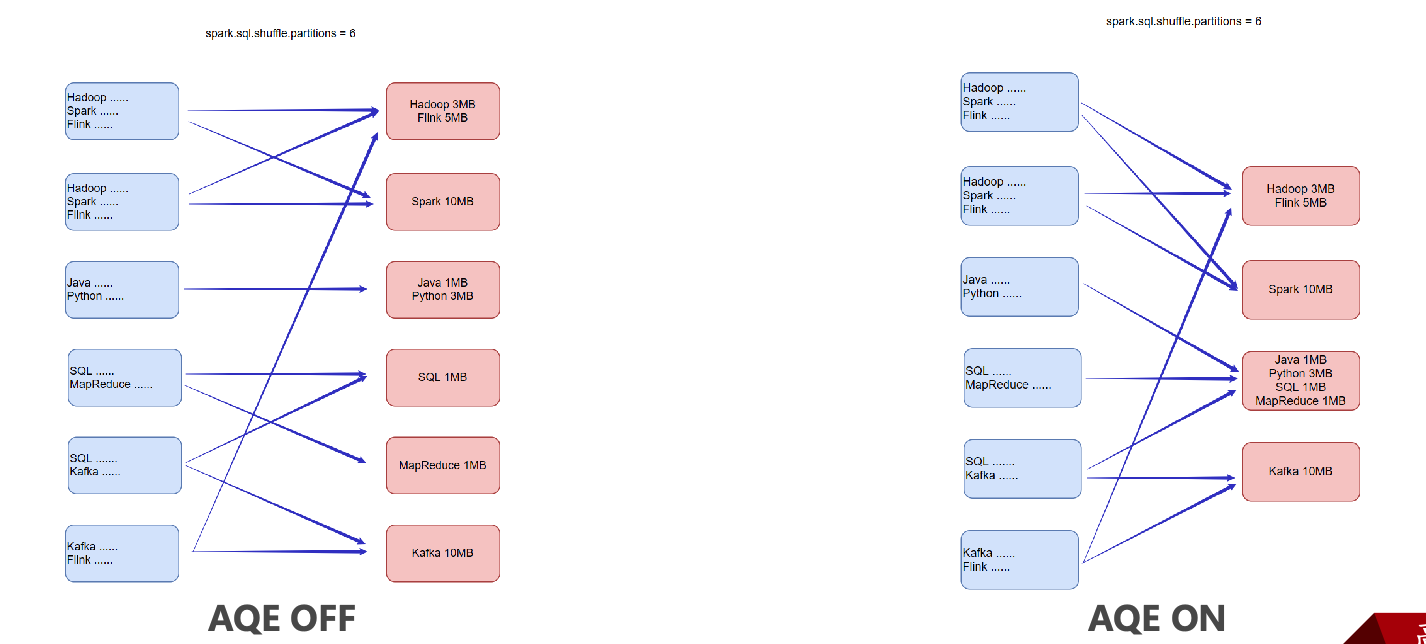
Dynamically coalescing shuffle partitions 动态合并
用户可以在开始设置相对较多的 shuffle 分区数,AQE 会在运行时将相邻的小分区合并为较大的分区。
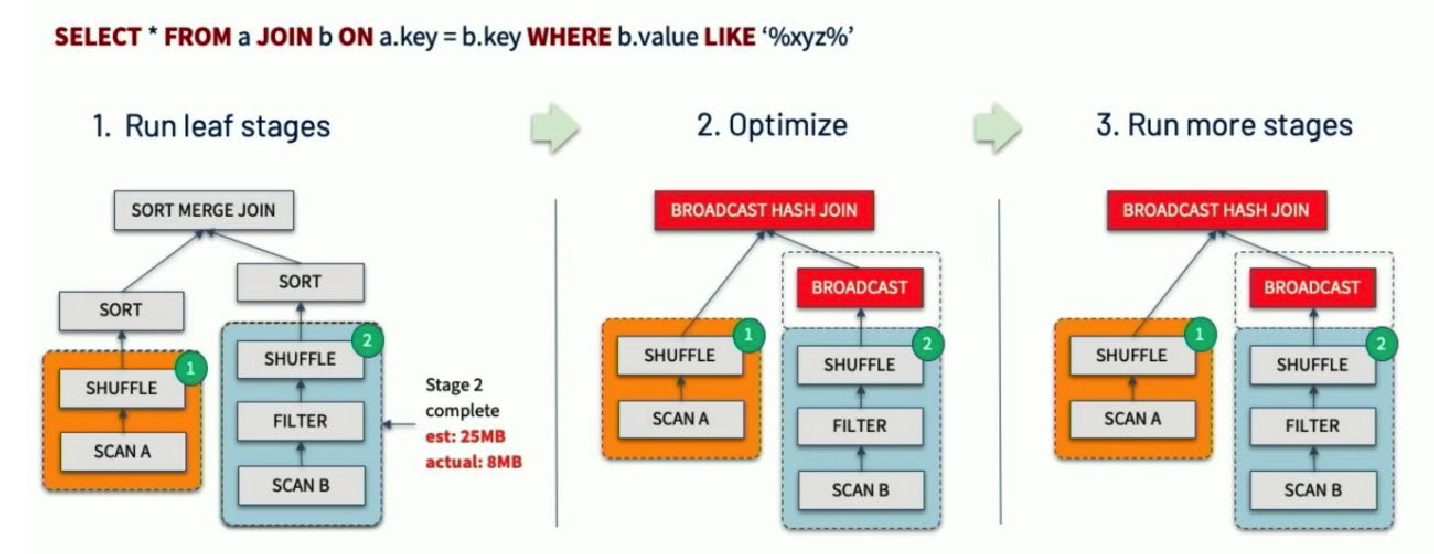
Dynamically switching join strategies 动态调整 Join 策略
可能由于缺少统计信息或者错误估计大小,而在实际执行阶段,右表的实际大小低于广播阈值(10MB),自适应优化可以在运行时将 sort merge join 转换成 broadcast hash join,从而进一步提升性能。
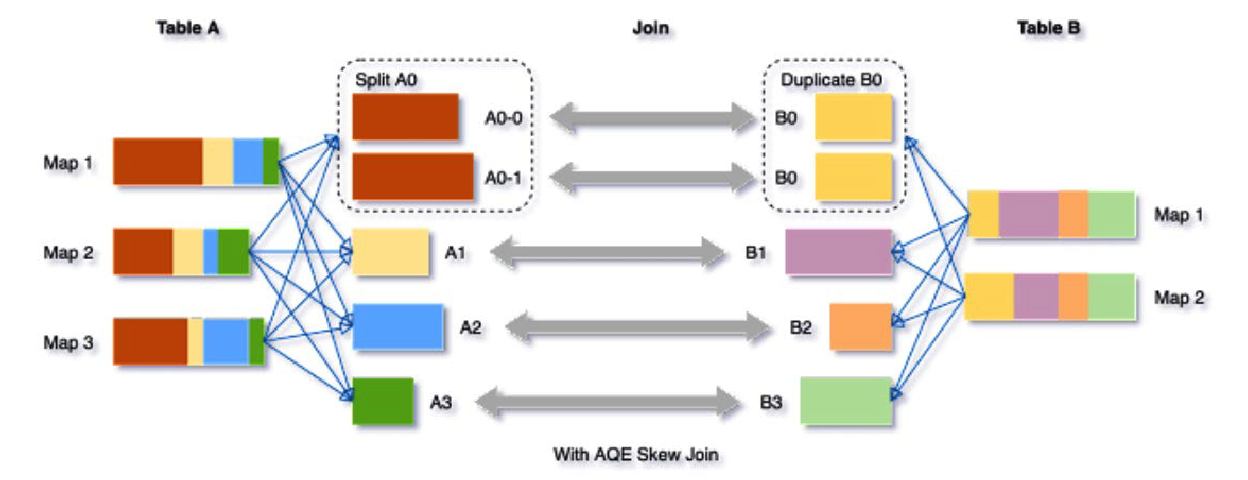
Dynamically optimizing skew joins 动态优化倾斜 Join
在 AQE 从 shuffle 文件统计信息中检测到任何倾斜后,它可以将倾斜的分区分割成更小的分区,并将它们与另一侧的相应分区连接起来。这种优化可以并行化处理倾斜分区,获得更好的整体性能。
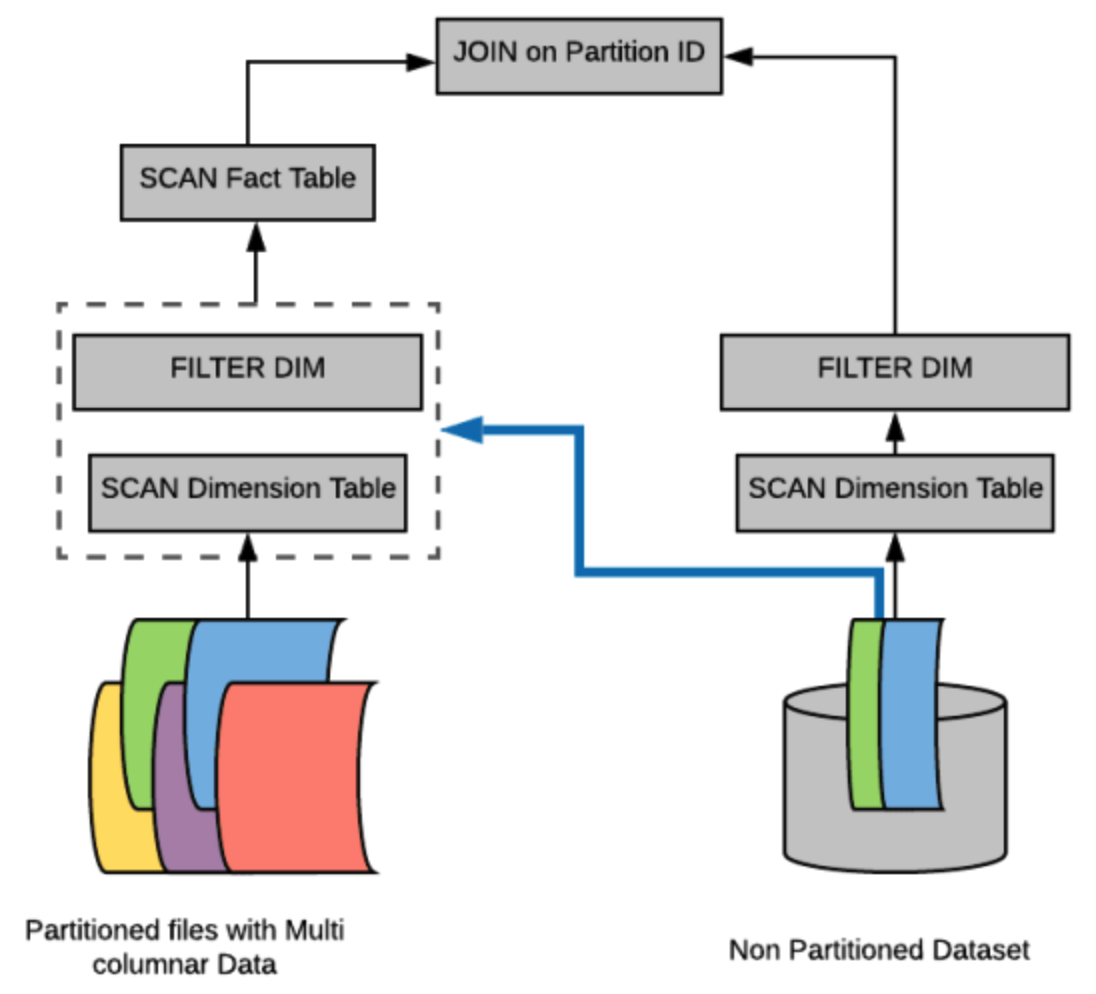
Dynamic Partitions Pruning 动态分区裁剪(SparkSQL)
当优化器在编译时无法识别可跳过的分区时,可以使用“动态分区裁剪”,即基于运行时推断的信息来进一步进行分区裁剪。
在一些连接操作中,我们可以通过识别维度表过滤之后的分区来裁剪从事实表中读取的分区。
增强的 Python API:PySpark 和 Koalas
Koalas 通过在 Apache Spark 上实现 Pandas DataFrame API,使数据科学家在与大数据交互时更有效率。
import pandas as pd
import numpy as np
import databricks.koalas as ks
from pyspark.sql import SparkSession
# 基于Pandas DataFrame构建
pdf = pd.DataFrame(np.random.randn(6,4), index=list('abcdef'), columns=list('ABCD'))
kdf1 = ks.from_pandas(pdf)
# 基于SparkSession构建
spark = ...
sdf = spark.createDataFrame(pdf) # 先转为Spark DataFrame
kdf2 = sdf.to_koalas() # 再转为Koalas DataFrame
# 直接创建
kdf3 = ks.DataFrame()
核心回顾
原思维导图文件:Spark核心概念.xmind
下篇决策树