概述
集成学习
集成学习方法使用多种学习算法来获得比单独使用某一种学习算法更好的预测性能。在现在的各种算法竞赛中,随机森林、梯度提升树(GBDT)、Xgboost 等集成算法的身影也随处可见。
常用的集成算法有:
- 装袋法(Bagging,Boostrap Aggregating):建立多个相互独立的基学习器(base estimator),采用投票或平均的方法得到预测结果。代表模型是随机森林。
- 提升法(Boosting):基于上一个基学习器,使那些被错误分类的样本可以得到更大的关注,利用调整后的样本训练得到下一个基学习器。代表模型有Adaboost和梯度提升树。
- 堆叠法(Stacking):以两层为例,第一层由多个基学习器组成,其输入为原始训练集,第二层的模型则是以第一层基学习器的输出作为特征加入训练集进行训练。
sklearn 中的集成算法
| 类 | 功能 |
|---|---|
| ensemble.AdaboostClassifier | Adaboost 分类 |
| ensemble.AdaBoostRegressor | Adaboost 回归 |
| ensemble.BaggingClassifier | Bagging 分类 |
| ensemble.BaggingRegressor | Bagging 回归 |
| ensemble.ExtraTreesClassifier | Extra-trees 分类(超树,极端随机树) |
| ensemble.ExtraTreesRegressor | Extra-tress 回归 |
| ensemble.GradienBoostingClassifier | 梯度提升分类 |
| ensemble.GradienBoostingRegressor | 梯度提升回归 |
| ensemble.IsolationForest | 隔离森林 |
| ensemble.RandomForestClassifier | 随机森林分类 |
| ensemble.RandomForestRegressor | 随机森林回归 |
| ensemble.RandomTreesEmbedding | 完全随机树的集成 |
| ensemble.VotingClassifier | 用于不合适学习器的软投票/多数规则分类器 |
RandomForestClassifier
class sklearn.ensemble.RandomForestClassifier(n_estimators=100, *, criterion=’gini’, max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=’auto’, max_leaf_nodes=None, min_impurity_decrease=0.0, bootstrap=True, oob_score=False, n_jobs=None, random_state=None, verbose=0, warm_start=False, class_weight=None, ccp_alpha=0.0, max_samples=None)
随机森林是非常具有代表性的 Bagging 集成算法,它的所有基学习器都是决策树。分类树组成的森林是随机森林分类器;回归树组成的森林是随机森林回归器。
重要参数
控制基学习器的参数
与[[2022-02-14-决策树|决策树]]的参数一致,单个决策树的准确率越高,随机森林的准确率也会越高。
n_estimators
森林中树的数量,即基学习器的数量。n_estimators 越大,模型的效果往往越好。
建模案例
random_state
随机森林的本质是一种 Bagging 算法,对基学习器的预测结果进行平均或用多数表决原则来决定集成学习器的结果。在红酒例子中,我们建立了25棵树的随机森林,单颗决策树的分类准确率在0.85上下浮动,当13颗树以上的树判断错误时,随机森林才会判断错误,其可能性为:
\[e_{random\_forest} = \sum_{i=13}^{25}C_{25}^i\varepsilon^i(1-\varepsilon)^{25-i}\]其中, \(\varepsilon\) 是一棵树判断错误的概率。可见,随机森林判断错误的概率非常小,这让随机森林在红酒数据集上的表现远远好于单颗决策树。
设想一下,如果随机森林里所有的树的判断结果是一致的(全对或全错),那随机森林无论应用何种集成原则来预测结果,都无法得到比单颗树更好的效果。
我们可以观察到,当 random_state 固定时,随机森林中生成的是一组固定的树,但每棵树依然是不一样的,这是用“随机挑选特征进行分枝”(splitter)的方法得到的随机性。可以证明,当这种随机性越大的时候,Bagging 的效果一般会越好,用 Bagging 算法时,基学习器应该是相互独立的。
bootstrap & oob_score
要让基学习器尽量都不相同,一种易于理解的方法是使用不同的训练集来进行训练,而 Bagging 是通过有放回的随机抽样技术来形成不同的训练数据,bootstrap 就是用来控制抽样技术的参数。
在一个含有 n 个样本的原始训练集中,有放回的随机抽样 n 次,得到一个大小为 n 的自助集。于是,我们可以创造任意多个互不相同的自助集。bootstrap 参数默认为 True,代表采用这种有放回的随机抽样技术;否则,将直接使用整个原始训练集。
由于是有放回的,一些样本可能在一个自助集中出现多次,而其他一些样本可能被忽略。一般来说,自助集大约会包含 63% 的原始数据。
\[\lim_{n \to +\infty}1-(1-\frac{1}{n})^n = 1-\frac{1}{e} \approx 0.632\]因此,当 n 足够大时,会有约 37% 的训练集被浪费掉,没有参与建模,这些数据被称为袋外数据(out of bag data,oob)。在使用随机森林时,我们可以不划分训练集和测试集,只需要用袋外数据来测试我们的模型即可。如果希望使用袋外数据来测试,则需要在实例化时设置 oob_score 参数为 True(默认 False)。训练完毕之后,我们可以用 rfc.oob_score_ 来查看在袋外数据上的测试结果。
小结
相较于决策树,随机森林有一些不同之处:
- 四个特殊参数:
n_estimators、random_state、boostrap、oob_score - 两个特殊属性:
-
estimators_:随机森林中树的列表 -
oob_score_:袋外得分 -
feature_importances_:特征的重要性
-
- 五个常用接口:
apply、fit、predit、score、predict_proba
RandomForestRegressor
class sklearn.ensemble.RandomForestRegressor(n_estimators=100, *, criterion=’squared_error’, max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=’auto’, max_leaf_nodes=None, min_impurity_decrease=0.0, bootstrap=True, oob_score=False, n_jobs=None, random_state=None, verbose=0, warm_start=False, ccp_alpha=0.0, max_samples=None)
除了参数 Criterion,所有的参数、属性和接口,全部和 [[2022-04-05-随机森林#RandomForestClassifier|随机森林分类器]]一致。
重要参数、属性和接口
criterion
回归树衡量分枝质量的指标有:squared_error, absolute_error, poisson
重要接口
apply、fit、predict、score,但随机森林回归器没有 predict_proba 接口。
实例:用随机森林回归填补缺失值
在这个案例中,我们将使用零、均值、和随机森林回归来填补缺失值,并验证这几种状况下的拟合效果。
机器学习中调参的基本思想
在机器学习中,我们用来衡量模型在未知数据上的准确率的指标,叫做泛化误差(Genelization error)。
泛化误差受到模型的结构(复杂度)影响,两者关系如下图所示:
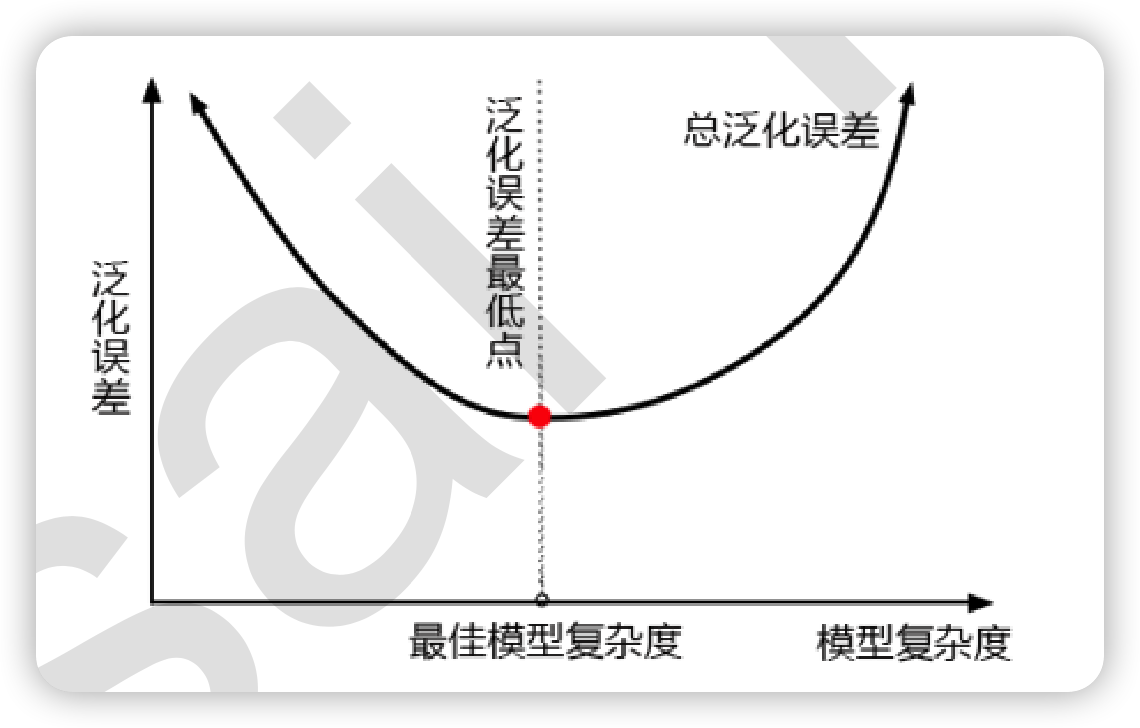
基于经验,几个重要参数对随机森林算法的复杂度的影响程度如下:
| 参数 | 对模型复杂度的影响 | 影响程度 |
|---|---|---|
| n_estimators | 提升至平稳,不影响单个基学习器的复杂度 |
|
| max_depth | 默认最大深度,深度减少,模型更简单 |
|
| min_samples_leaf | 默认最小限制1,叶子样本数增加,模型更简单 |
|
| min_samples_split | 默认最小限制2,分枝样本树增加,模型更简单 |
|
| max_features | 默认auto,特征数量降低,模型更简单 | |
| criterion | 有增有减,一般使用gini | 看具体情况 |
实例:随机森林在乳腺癌数据上的调参
这一节,基于方差和偏差的关系,在乳腺癌数据上进行一次随机森林的调参。