第1章 Spark 框架概述
Spark 是什么
Apache Spark 是一个多语言引擎,用于在单节点机器或集群上执行数据工程、数据科学和机器学习。
Apache Spark™ is a multi-language engine for executing data engineering, data science, and machine learning on single-node machines or clusters.
Spark 有哪些特性
- 批处理/流式数据(Batch/streaming data)
- SQL分析(SQL analytics)
- 弹性数据科学(Data science at scale)
- 机器学习(Machine learning)
Spark 有哪些模块
核心SparkCore、SQL计算(SparkSQL)、流计算(SparkStreaming)、图计算(GraphX)、机器学习(MLib)
Spark 的运行模式
- 本地模式(Local)
- 集群模式(StandAlone、YARN、K8S)
- 云模式
Spark 的运行角色(对比 YARN)
- Master:集群资源管理(类同 ResourceManager)
- Worker:单机资源管理(类同 NodeManager)
- Driver:单任务管理者(类同 ApplicationMaster)
- Executor:单任务执行者(类同 YARN 容器内的 Task)
第2章 Spark 环境搭建-Local
略
第3章 Spark 环境搭建-Standalone
Standalone 架构
在 Standalone集群 上主要有3类进程:
- 主节点 Master:管理整个集群资源各个任务的 Driver;
- 从节点 Workers:管理每个机器的资源,分配对应的资源来运行 Executor(Task);
- 历史服务器 HistoryServer(可选):Spark Application 运行完成以后,保存事件日志数据至 HDFS,启动 HistoryServer 可以查看应用运行相关信息。
Standalone 环境安装操作
略
Spark 应用架构
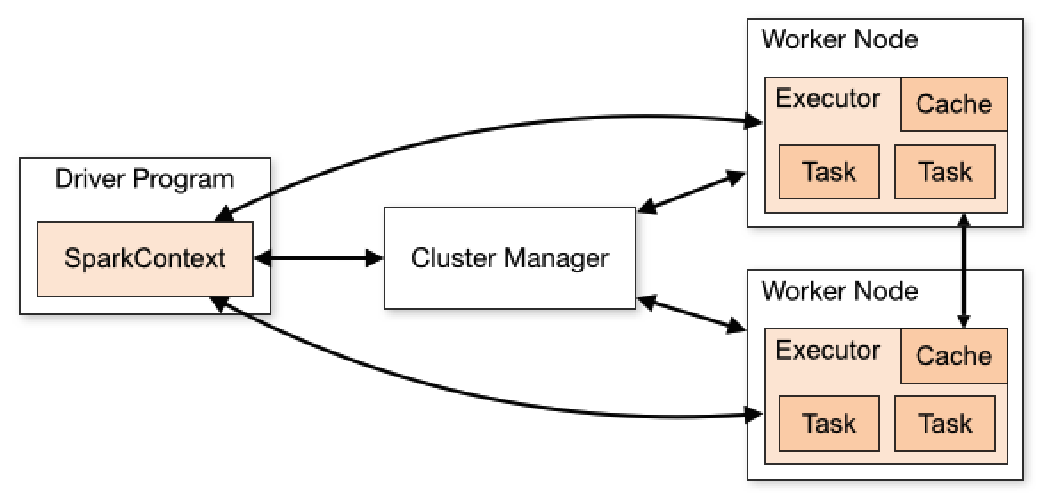
用户应用程序从最开始的提交到最终的计算执行,需要经历一下几个阶段:
- 用户程序创建
SparkContext时,新创建的SparkContext实例会连接到ClusterManager。Cluster Manager会根据用户提交时设置的 CPU 和内存等信息为本次提交分配计算资源,启动Executor; Driver会将用户程序划分为不同的执行阶段 Stage,每个执行阶段 Stage 由一组完全相同 Task 组成,这些 Task 分别作用于待处理数据的不同分区。在阶段划分完成和 Task 创建后,Driver会向Executor发送 Task;Executor在接收到 Task 后,会下载 Task 的运行时依赖,在准备好 Task 的执行环境后,会开始执行 Task,并且将 Task 的运行状态汇报给Driver;Driver会根据收到的 Task 的运行状态来处理不同的状态更新。Task 分为两种:一种是 Shuffle Map Task,它实现数据的重新洗牌,洗牌的结果保存到Executor所在节点的文件系统中;另外一种是 Result Task,它负责生成结果数据;Driver会不断地调用 Task,将Task发送到Executor执行,在所有的Task 都正确执行或者超过执行次数的限制仍然没有执行成功时停止。
Spark 运行层次结构
Spark Application 程序运行时三个核心概念:Job、Stage、Task,说明如下:
- Job:由多个 Task 的并行计算部分,一般 Spark 中的 action 操作(如 save、collect,后面进一步说明),会 生成一个 Job。
- Stage:Job 的组成单位,一个 Job 会切分成多个 Stage,Stage 彼此之间相互依赖顺序执行,而每个 Stage 是多个 Task 的集合,类似 map 和 reduce stage。
- Task:被分配到各个 Executor 的单位工作内容,它是 Spark 中的最小执行单位,一般来说有多少个 Paritition (物理层面的概念,即分支可以理解为将数据划分成不同 部分并行处理),就会有多少个 Task,每个 Task 只会处理单一分支上的数据。
第4章 Spark 环境搭建-Standalone HA
Spark Standalone 集群是 Master-Slaves 架构的集群模式,和大部分的 Master-Slaves 结构集群一样,存在着 Master 单点故障(SPOF)的问题。
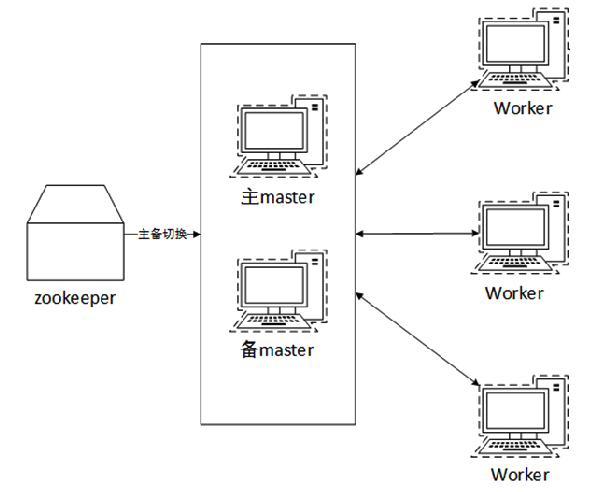
基于 Zookeeper 的 HA
ZooKeeper 的 Standby Master(Standby Masters with ZooKeeper)
ZooKeeper 提供了一个 Leader Election 机制,利用这个机制可以保证虽然集群存在多个 Master,但是只有一个 Active 的,其他的都是 Standby 状态。当 Active 的 Master 出现故障时,另外的一个 Standby Master 会被选举出来。由于集群的信息,包括 Worker、Driver 和 Application 的信息都已经持久化道文件系统中,因此在切换的过程中只会影响新的 Job 提交,对于正在进行的 Job 没有任何影响。
ZooKeeper 的集群整体架构如下图:
第5章 环境搭建-Spark on YARN
YARN 本身是一个资源调度框架,负责对运行在内部的计算框架进行资源调度管理。作为典型的计算框架,Spark 本身也是直接运行在 YARN 中,并接受 YARN 的调度。
SparkOnYarn 本质
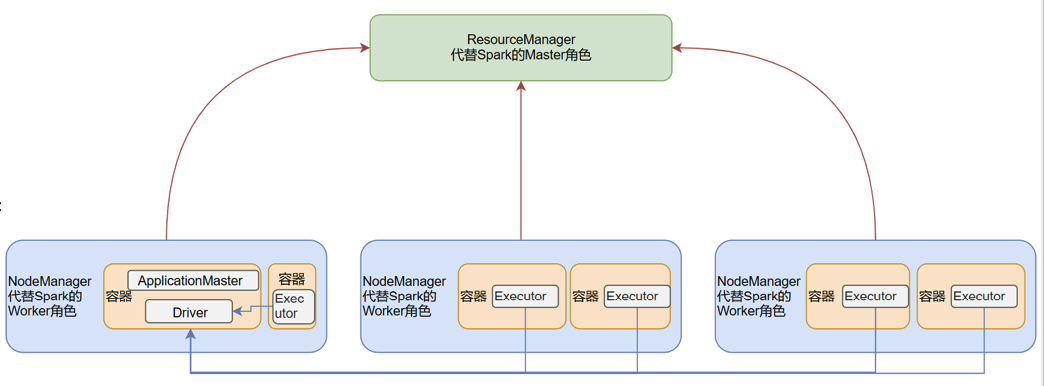
Master角色由 YARN 的ResourceManager担任Worker角色由 YARN 的NodeManager担任Driver角色运行在 YARN容器 内或提交任务的 客户端进程中Executor运行在 YARN 提供的容器内
部署模式 DeployMode
Spark on YARN 有两种运行模式(区别在于 Driver 运行的位置):
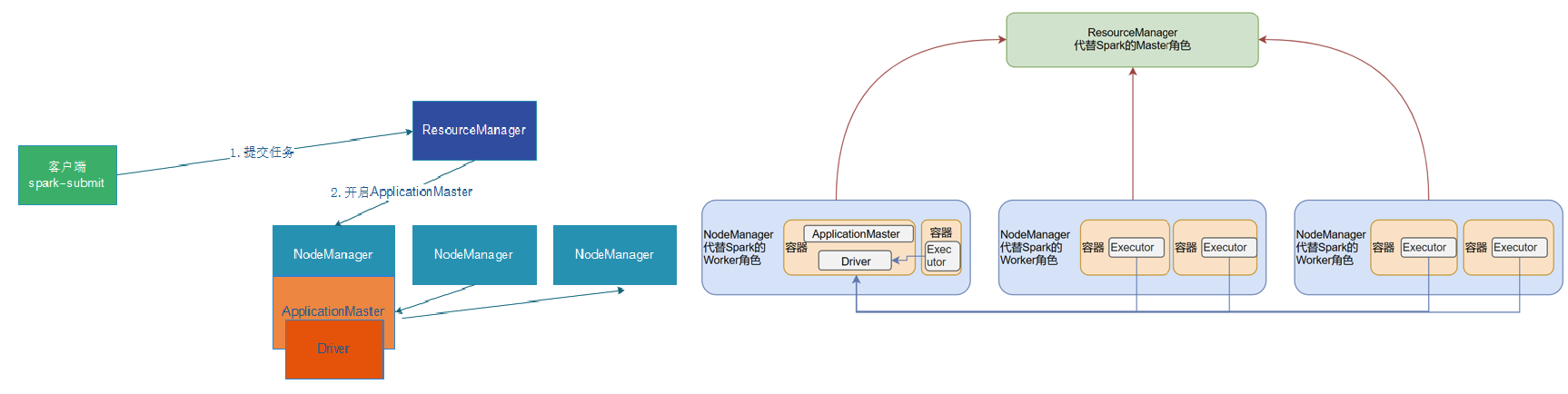
- Cluster 模式:Driver 运行在 YARN 容器内部,和 ApplicationMaster 在同一个容器内
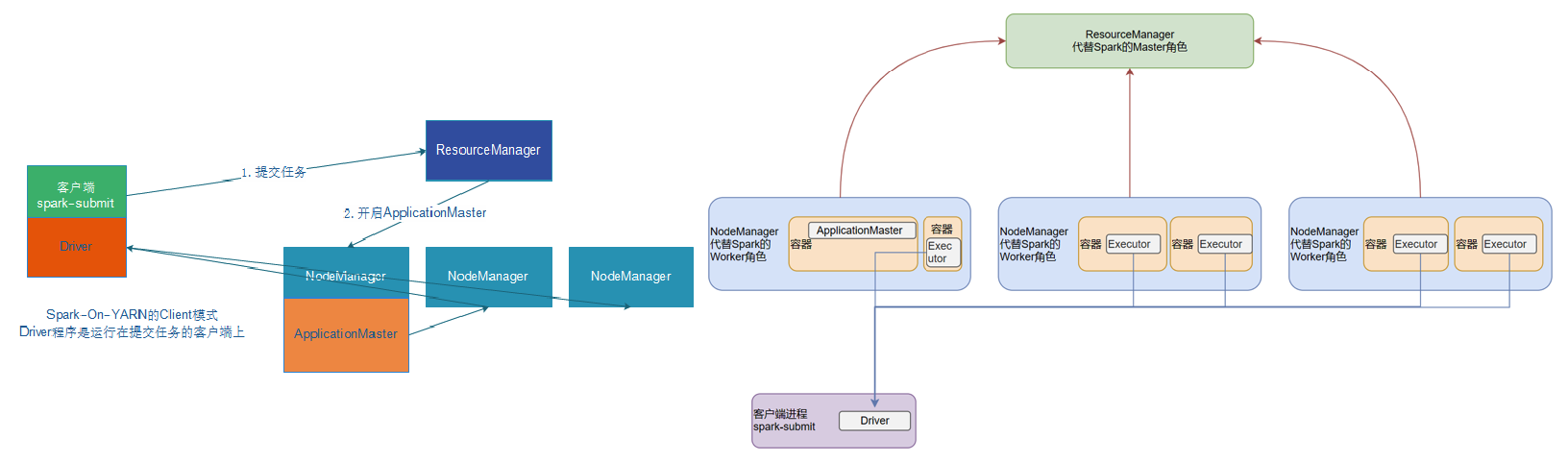
- Client 模式:Driver 运行在客户端进程中,比如 Driver 运行在 spark-submit 程序的进程中
两种模式对比
| Cluster模式 | Client模式 | |
|---|---|---|
| Driver运行位置 | YARN容器内 | 客户端进程内 |
| 通信效率 | 较高 | 较低 |
| 日志查看 | 日志输出在容器内,查看不方便 | 日志输出在客户端的标准输出流中,方便查看 |
| 生产可用 | 推荐 | 不推荐 |
| 稳定性 | 稳定 | 基于客户端进程,受到客户端进程影响 |
第6章 PySpark 库
框架 v.s. 类库
- 框架:可以独立运行,并提供编程结构的一种软件产品。例如,Spark 就是一个独立的框架。
- 类库:一堆别人写好的代码,你可以导入使用。例如,Pandas 就是 Python 的类库。
什么是 PySpark
现在说的 PySpark,指的是 Python 的运行类库
PySpark 是 Spark 官方提供的一个 Python 类库,内置了完全的 Spark API,可以通过 PySpark 类库来编写 Spark 应用程序,并将其提交到 Spark 集群中运行。
PySpark 类库和标准 Spark 框架的简单对比
| 功能 | PySpark | Spark |
|---|---|---|
| 底层语言 | Python | Scala(JVM) |
| 上层语言支持 | 仅Python | Python\Java\Scala\R |
| 集群化\分布式运行 | 仅支持单机 | 支持 |
| 定位 | Python库(客户端) | 标准框架(客户端和服务端) |
| 是否可以Daemon运行 | NO | Yes |
| 使用场景 | 本地开发调试Python程序 | 生产环境集群化运行 |
第7章 本机开发环境搭建
应用入口:SparkContext
Spark Application 程序入口为:SparkContext,分以下两步构建:
- 创建
SparkConf对象 - 基于 SparkConf 对象,创建
SparkContext对象
conf = SparkConf().setAppName(appName).setMaster(master)
sc = SparkContext(conf=conf)
第8章 分布式代码执行分析
Spark 集群角色回顾(以 YARN 为例)
当 Spark Application 运行在集群上时,主要由四个部分组成,如下示意图:
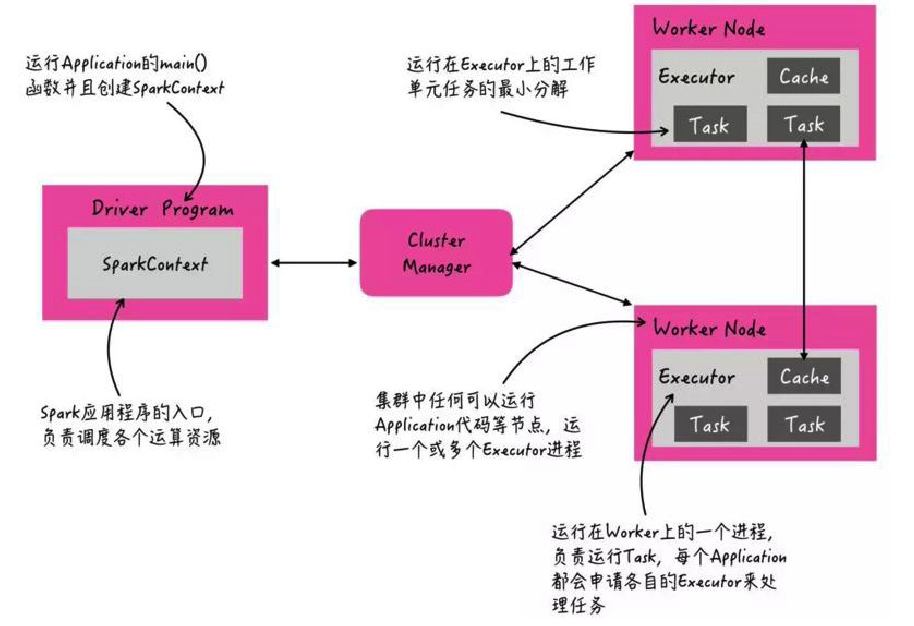
- Master(ResourceManager):集群大管家,整个集群的资源管理和分配
- Worker(NodeManager):单个机器的管家,负责在单个服务器上提供运行容器,管理当前机器的资源
- Driver:单个 Spark 任务的管理者,管理 Executor 的任务执行和任务分解分配,,类似 YARN 的 ApplicationMaster
- Executor:具体干活的进程,Spark 的工作任务(Task)都由 Executor 来负责执行
分布式代码执行分析
简单分析后得知:
- SparkContext 对象的构建以及 Spark 程序的退出,由 Driver 负责执行
- 具体的数据处理步骤,由 Executor 在执行
其实简单来说就是:
- 非数据处理的部分由 Driver 工作
- 数据处理的部分由 Executor 工作
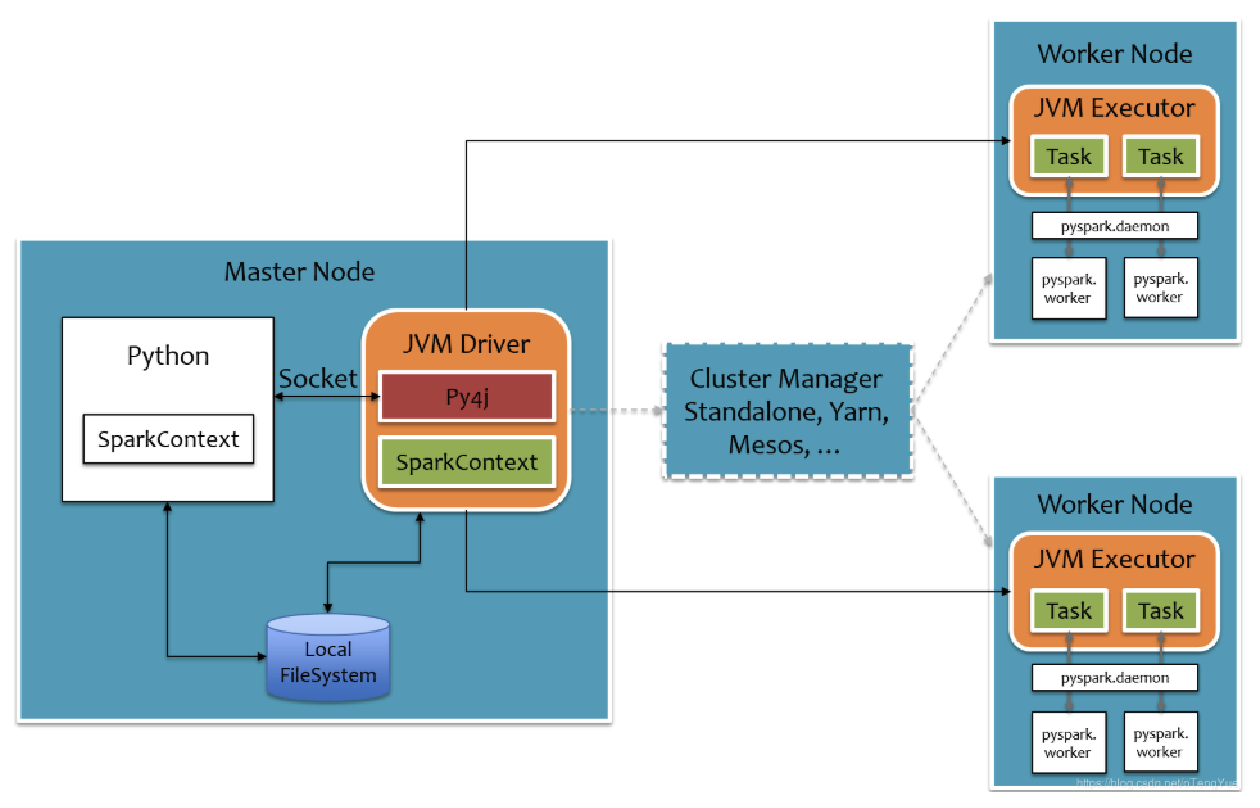
Pythoh on Spark 执行原理
PySpark 宗旨是在不破坏 Spark 已有的运行时架构,在 Spark 架构外层包装一层 Python API,借助 Py4j 实现 Python 和 Java 的交互,进而实现通过 Python 编写 Spark 应用程序,其运行时架构如下图所示。