第1章 RDD 详解
为什么需要 RDD
分布式计算需要:
- 分区控制
- Shuffle 控制
- 数据存储\序列化\发送
- 数据计算 API
- 等一系列功能
什么是 RDD
定义
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据抽象,代表一个不可变、可分区、可并行计算的集合。
- Resilient:RDD 中的数据可以存储在内存中或者磁盘中
- Distributed:RDD 中的数据是分布式存储的,可用于分布式计算
-
Dataset:一个数据集合,用于存放数据的
- RDD,是 Spark 中最基本的数据抽象,代表一个不可变、可分区、可并行计算的集合。
- 所有的运算以及操作都建立在 RDD 数据结构的基础之上。
- 可以认为 RDD 是分布式的列表 List 或数组 Array,抽象的数据结构,RDD 是一个抽象类(Abstract Class)和泛型(Generic Type)。
RDD 的五大特性
- A list of partitions(一系列的分片)
- A function for computing each split(一个函数可计算每一个分片)
- A list of dependencies on other RDDs(RDD 间有依赖关系:RDD1 –> RDD2 –> RDD3)
- Optionally,a Partitioner for Key-value RDDs(可选,Key-Value 型的 RDD 可以有分区器)
- Optionally, a list of preferred locations to compute each split on(可选,尽可能在本地运行)
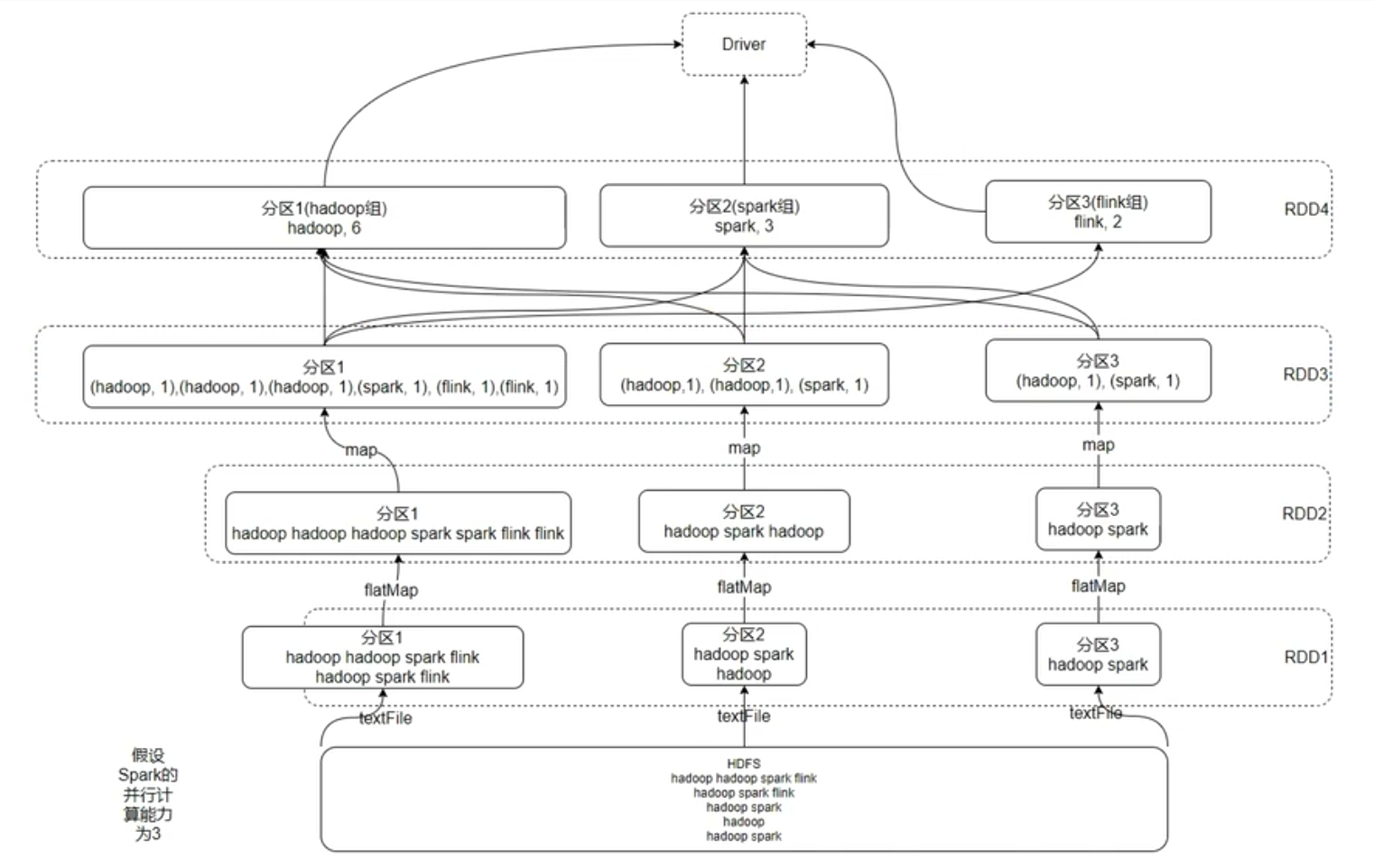
第2章 RDD 编程入门
RDD 的创建
并行化创建(集合对象)
API:
SparkContext.parallelize(_c_, _numSlices=None_)
代码:
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName('myApp').setMaster('local')
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9]) # 默认分区数
print(rdd.getNumPartitions())
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9], 3) # 指定分区数
print(rdd.getNumPartitions())
print(rdd.collect())
读取外部数据源
API:
SparkContext.textFile(_name_, _minPartitions=None_, _use_unicode=True_)
支持本地文件、HDFS、S3协议
代码:
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName('myApp').setMaster('local')
sc = SparkContext(conf=conf)
sc.setLogLevel('INFO')
file_rdd1 = sc.textFile('./data/input/words.txt')
print(file_rdd1.getNumPartitions())
print(file_rdd1.collect())
file_rdd2 = sc.textFile('./data/input/words.txt', 3)
print(file_rdd2.getNumPartitions())
file_rdd3 = sc.textFile('./data/input/words.txt', 100)
print(file_rdd3.getNumPartitions())
API:
SparkContext.wholeTextFiles(path, minPartitions=None, use_unicode=True)
适合读取一堆小文件
同样支持本地文件、HDFS、S3协议
代码:
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName('myApp').setMaster('local')
sc = SparkContext(conf=conf)
rdd = sc.wholeTextFiles('./data/input/tiny_files', 3)
print(rdd.collect())
RDD 算子
算子是什么
分布式集合对象上的 API 称为算子。
分成两类:
- 转换(Transformation)算子:返回值仍旧是一个 RDD 的
- 动作(Action)算子:返回值不是 RDD 的
懒加载:转换算子只是在构建执行计划,动作算子是一个指令让执行计划开始工作。
常用转换算子
map
将方法应用到 RDD 中的每个元素
API:
RDD.map(f, preservesPartitioning=False)
代码:
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName('myApp').setMaster('local')
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9], 3)
# def double(num):
# return num * 2
# print(rdd.map(double).collect())
print(rdd.map(lambda x: x * 2).collect())
flatMap
先进行 map 操作,再进行 展平 操作
API:
RDD.flatMap(f, preservesPartitioning=False)
代码:
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName('myApp').setMaster('local')
sc = SparkContext(conf=conf)
rdd = sc.parallelize(["hello spark", "hello apache", "hello replit"])
rdd2 = rdd.flatMap(lambda x: x.split(" "))
print(rdd2.collect())
reduceByKey
针对 KV 型 RDD,自动按照 key 分组,然后对 value 应用聚合函数。
聚合逻辑如下图:
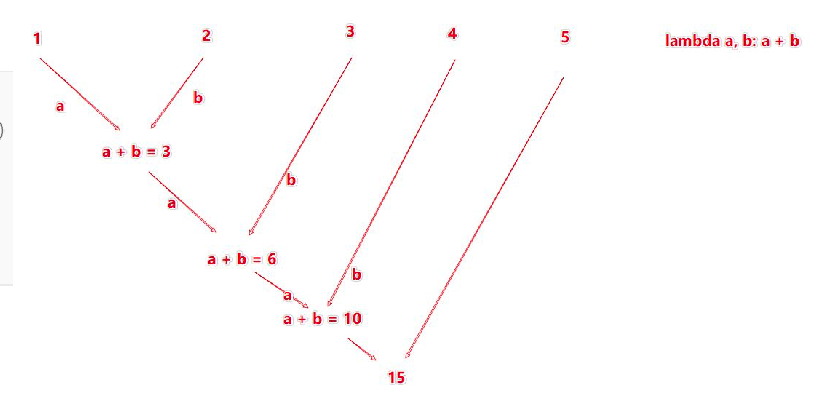
API:
RDD.reduceByKey(func, numPartitions=None, partitionFunc=<function portable_hash>)
代码:
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName('myApp').setMaster('local')
sc = SparkContext(conf=conf)
# 实现 WordCount
rdd = sc.textFile('./data/input/words.txt')
rdd1 = rdd.flatMap(lambda x: x.split(" "))
rdd2 = rdd1.map(lambda x: (x, 1))
rdd3 = rdd2.reduceByKey(lambda a, b: a + b)
print(rdd3.collect())
mapValues
针对KV 型 RDD,对 value 应用 map 函数,不影响 key
API:
RDD.mapValues(f)
代码:
rdd = sc.parallelize([('a', 1), ('b', 2), ('c', 3)])
print(rdd.mapValues(lambda x: x * 2).collect())
groupBy
将 RDD 的数据进行分组
API:
RDD.groupBy(f, numPartitions=None, partitionFunc=<function portable_hash>)
代码:
rdd = sc.parallelize([('a', 1), ('b', 2), ('c', 1), ('a', 1)])
result = rdd.groupBy(lambda x: x[0])
print(result.map(lambda x: (x[0], list(x[1]))).collect())
filter
过滤想要保留的数据,返回是 True 的数据被保留,返回时 False 的数据被丢弃
API:
RDD.filter(f)
代码:
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9], 3)
# 筛选偶数
print(rdd.filter(lambda x: x % 2 == 0).collect())
distinct
对 RDD 数据进行去重
API:
RDD.distinct(numPartitions=None)
代码:
rdd = sc.parallelize([('a', 1), ('b', 2), ('c', 1), ('a', 1)])
print(rdd.distinct().collect())
union
一个 RDD 和另一个 RDD 合并
只合并,不会去重
不同类型的 RDD 也可以合并
API:
RDD.union(other)
代码:
rdd1 = sc.parallelize([1, 2, 3])
rdd2 = sc.parallelize(['a', 'b', 'c'])
print(rdd1.union(rdd2).collect())
join、leftOuterJoin
类似于 SQL 中的 join
但是,只适用于二元元组,且不能指定关联条件
API:
RDD.join(other, numPartitions=None)
RDD.leftOuterJoin(other, numPartitions=None)
代码:
rdd1 = sc.parallelize([('a', 'wang'), ('a', 'li'), ('b', 'zhang'),
('c', 'xu')])
rdd2 = sc.parallelize([('a', 'sales'), ('b', 'tech')])
print(rdd1.join(rdd2).collect())
print(rdd1.leftOuterJoin(rdd2).collect())
intersection
求两个 RDD 的交集
API:
RDD.intersection(other)
代码:
rdd1 = sc.parallelize(['a', 'b', 'c'])
rdd2 = sc.parallelize(['c', 'c', 'd'])
print(rdd1.intersection(rdd2).collect())
glom
按照分区,将 RDD 划分成 List
API:
RDD.glom()
代码:
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9], 3)
print(rdd.glom().collect())
groupByKey
针对 KV 型 RDD,自动按照 key 分组
API:
RDD.groupByKey(numPartitions=None, partitionFunc=<function portable_hash>)
代码:
rdd = sc.parallelize([('a', 1), ('a',1), ('b',1), ('b',1), ('a',1)])
groupby_rdd = rdd.groupByKey()
print(groupby_rdd.mapValues(lambda x: sum(x)).collect())
sortBy
对 RDD 进行排序,基于你指定的排序依据
API:
RDD.sortBy(keyfunc, ascending=True, numPartitions=None)
代码:
rdd = sc.parallelize([5, 2, 3, 7, 9, 1, 6, 8, 4], 3)
print(rdd.sortBy(lambda x: x, ascending=True, numPartitions=3).collect())
sortByKey
针对 KV 型 RDD,按照 key 进行排序
API:
RDD.sortByKey(ascending=True, numPartitions=None, keyfunc=<function RDD.<lambda>>)
代码:
rdd = sc.parallelize([('a', 1), ('B', 1), ('A', 1), ('b', 1)])
# print(rdd.sortByKey(True).collect())
print(rdd.sortByKey(True, keyfunc=lambda x: str(x).lower()).collect())
常用动作算子
countByKey
统计 key 出现的次数(一般适用于 KV 型 RDD)
结果为 dict
API:
RDD.countByKey()
代码:
rdd = sc.parallelize([('a', 1), ('b', 2), ('c', 1), ('a', 1)])
print(rdd.countByKey())
collect
将 RDD 各个分区内的数据收集到 Driver 中
结果为 list
API:
RDD.collect()
reduce
对 RDD 数据集按照指定方法进行聚合
方法中参数和返回值要求类型一致
API:
RDD.reduce(f)
代码:
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9], 3)
print(rdd.reduce(lambda a, b: a + b))
fold
和 [[2021-12-10-SparkCore#reduce|reduce]] 类似,按照指定方法进行聚合,但是是带有初始值的
这个初始值会作用在:分区内聚合、分区间聚合
API:
RDD.fold(zeroValue, op)
代码:
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9], 3)
print(rdd.fold(10, lambda a, b: a + b))
first
取出 RDD 的第一个元素
API:
RDD.first()
take
取 RDD 中前 N 个元素
结果为 list
API:
RDD.take(num)
top
对 RDD 进行降序排序后,取前 N 个
API:
RDD.top(num, key=None)
count
统计 RDD 中有多少条数据
API:
RDD.count()
takeSample
随机抽样
参数 withReplacement 表示抽样是否允许放回:True 表示允许,False 表示不允许
API:
RDD.takeSample(withReplacement, num, seed=None)
代码:
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9], 3)
print(rdd.takeSample(True, 3))
takeOrdered
对 RDD 排序后取前 N 个
与 [[2021-12-10-SparkCore#top|top]] 不同的是,既可以升序(默认),也可以通过可选的方法实现降序
API:
RDD.takeOrdered(num, key=None)
代码:
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9], 3)
print(rdd.takeOrdered(5))
print(rdd.takeOrdered(5, key=lambda x: -x))
foreach
和 [[2021-12-10-SparkCore#map|map]] 类似,将方法应用到 RDD 中的每个元素,但是这个方法没有返回值
在 Executor 中分布式执行,不需要向 Driver 汇报,因此在某些场景下更加高效。
API:
RDD.foreach(f)
代码:
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9], 3)
rdd.foreach(lambda x: print(x))
saveAsTextFile
将 RDD 的数据写入到文本文件中,支持本地文件、HDFS 等
和 foreach 类似,由 Executor 分布式执行,是不经过 Driver 的
API:
RDD.saveAsTextFile(path, compressionCodecClass=None)
分区操作算子
mapPartitions
与 [[2021-12-10-SparkCore#map|map]] 不同的是,mapPartitions 中传送的是每个分区的数据,作为一个迭代器(iterator)对象传入过来。
API:
RDD.mapPartitions(f, preservesPartitioning=False)
代码:
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9], 3)
def f(iterator):
yield sum(iterator)
print(rdd.mapPartitions(f).collect())
foreachPartition
和 [[2021-12-10-SparkCore#foreach|foreach]] 类似,但一次处理的是一整个分区数据
API:
RDD.foreachPartition(f)
代码:
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9], 3)
def f(iterator):
for i in iterator:
print(i * 2)
rdd.foreachPartition(f)
partitionBy
对 RDD 进行自定义分区操作
API:
RDD.partitionBy(numPartitions, partitionFunc=<function portable_hash>)
代码:
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9], 3)
rdd = rdd.map(lambda x: (x, 1))
print(rdd.partitionBy(2, partitionFunc=lambda x: x % 2).glom().collect())
repartition
修改 RDD 的分区数量(重新分区)
注意:对分区的数量进行操作,一定要慎重
API:
RDD.repartition(numPartitions)
coalesce
与 [[2021-12-10-SparkCore#repartition|repartition]] 类似,可以修改 RDD 的分区数据
不同的是,第2个参数表示增加分区是否需要 shuffle,默认是 False
如果不指定 shuffle=True,则只能减少分区,更加“安全”
API:
RDD.coalesce(numPartitions, shuffle=False)